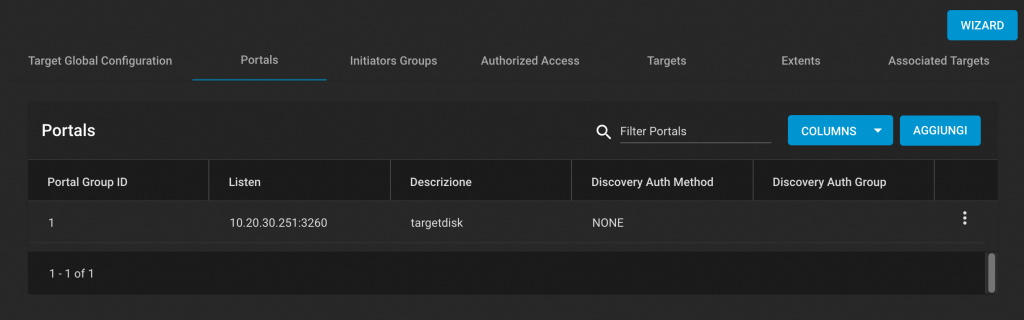
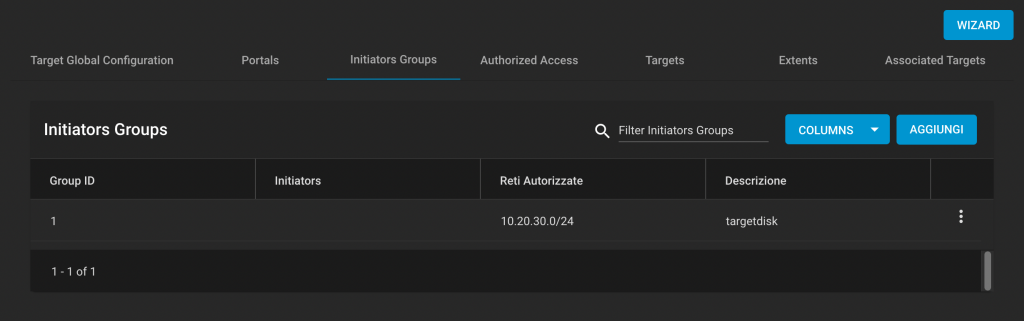
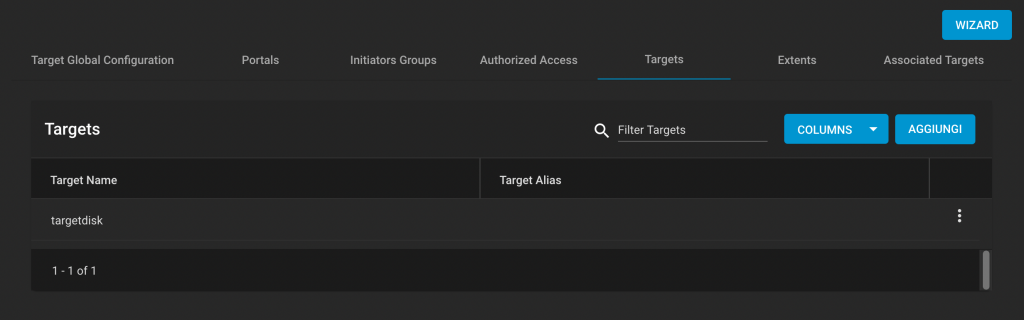
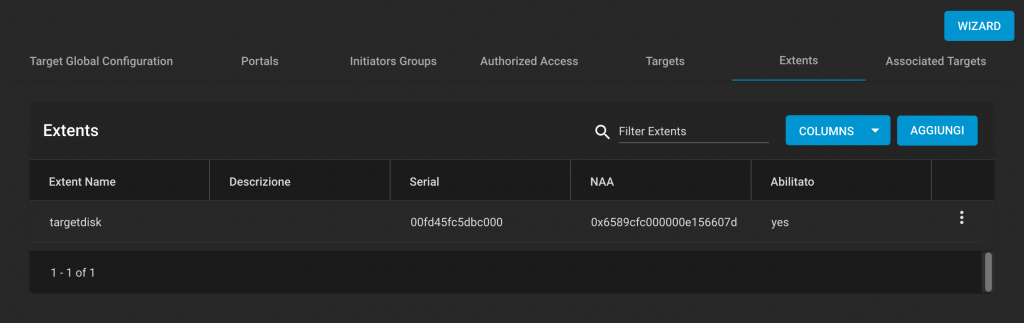
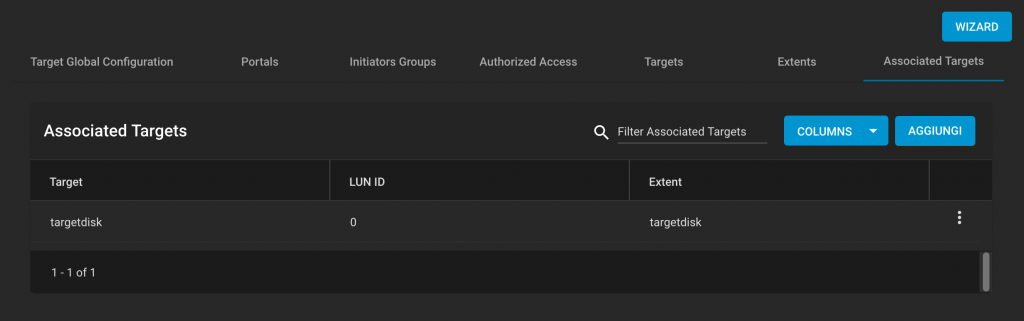
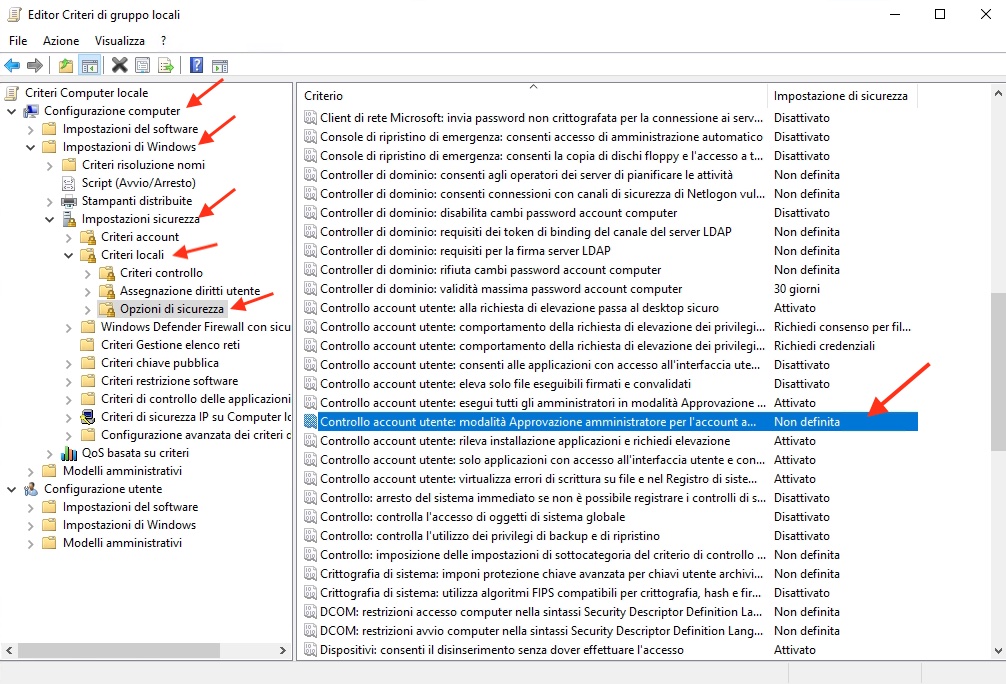
Greg writes:
Here’s a quick and clean way to swap data in place without having to resort to using a temporary memory location:
short *aPtr, *bPtr;
*aPtr ^= *bPtr;
*bPtr ^= *aPtr;
*aPtr ^= *bPtr;
While this is mathematically cool, lets take a look at the assembly code that it generates and see what’s really happening. First, for comparison, a couple of more pedestrian implementations:
void swap2(short *aPtr, short *bPtr) {
short a = *aPtr; // a version with two temporaries
short b = *bPtr;
*aPtr = b;
*bPtr = a;
}
void swap1(short *aPtr, short *bPtr) {
short a = *aPtr; // a version with one temporary
*aPtr = *bPtr;
*bPtr = a;
}
void swap0(short *aPtr, short *bPtr) {
*aPtr ^= *bPtr; // Greg’s tip
*bPtr ^= *aPtr;
*aPtr ^= *bPtr;
}
Now, let’s take a look at what the compiler actually generates for these functions. (I’m using CodeWarrior with all optimizations on for these examples.)
Recall that as processsors have gotten faster, memory has not. For instance 1/80ns (the speed on memory in most Macintoshes) = 12.5 MHz. This means that if adjacent instructions have to address memory with no intervening computation, it’s as if the processor has slowed to 12.5MHz.
First the 68K compiler, starting with the two temp case:
Name="swap2"(6) Size=26
MOVEA.L $0004(A7),A1
MOVEA.L $0008(A7),A0
MOVE.W (A1),D0
MOVE.W (A0),D1
MOVE.W D1,(A1)
MOVE.W D0,(A0)
RTS
gnoring the two MOVEA.L’s which set up the address registers and the return, this takes four instructions, all of which touch memory. Notice, however that there are no cases where the result of an instruction is used an an input to the next instruction, meaning that most of the instructions can overlap in the processor pipeline.
Next with one temp:
Name="swap1"(4) Size=24
MOVEA.L $0004(A7),A1
MOVEA.L $0008(A7),A0
MOVE.W (A1),D0
MOVE.W (A0),(A1)
MOVE.W D0,(A0)
RTS
Here we have three instructions, all accessing memory and all can overlap. This is smaller than the example above. Whether it is faster depends on the relative timing of the MOVE.W (A0),(A1) instruction. (If anyone wants to time this, I’ll print the results.)
Now Greg’s ‘tip’:
Name="swap0"(1) Size=30
MOVEA.L $0004(A7),A1
MOVEA.L $0008(A7),A0
MOVE.W (A0),D0
EOR.W D0,(A1)
MOVE.W (A1),D0
EOR.W D0,(A0)
MOVE.W (A0),D0
EOR.W D0,(A1)
RTS
This generates six instructions, all of which touch memory. Furthermore three of these are read-modify-write cycles, which are slower that a read or write and each instruction depends on the result of the instructon directly before it, meaning it won’t overlap in the pipeline, making this both the largest and slowest implementation of the three.
Now lets look at the PowerPC code:
Name=".swap2"(6) Size=20
lha r0,0(r3)
lha r5,0(r4)
sth r5,0(r3)
sth r0,0(r4)
blr
Name=".swap1"(4) Size=20
lha r5,0(r3)
lha r0,0(r4)
sth r0,0(r3)
sth r5,0(r4)
blr
Note that both of the versions with temporaries generated the same code (4 instructions, all touching memory but pipelineable). This is because RISC processors typically don’t have memory to memory operations; instead, they must move data to a register before operating on it.
Now our ‘tip’:
Name=".swap0"(1) Size=52
lha r5,0(r4)
lha r0,0(r3)
xor r0,r0,r5
sth r0,0(r3)
lha r5,0(r3)
lha r0,0(r4)
xor r0,r0,r5
sth r0,0(r4)
lha r4,0(r4)
lha r0,0(r3)
xor r0,r0,r4
sth r0,0(r3)
blr
This implementation is by far the largest and slowest, generating 12 instructions, including 6 memory accesses. Furthermore there are 2 pipeline stalls. Clearly this implementation is the largest and slowest of all.
The moral of the story is: don’t get tricky. C programmers often try to minimize the number of lines of C in their program without consideration for what the compiler will generate. When in doubt, write clear code and give the optimizer a chance to maximize performance. Look at the compiler output. Your code will be easier to debug and probably faster too.
’Till next time